Firecrawl
详细说明
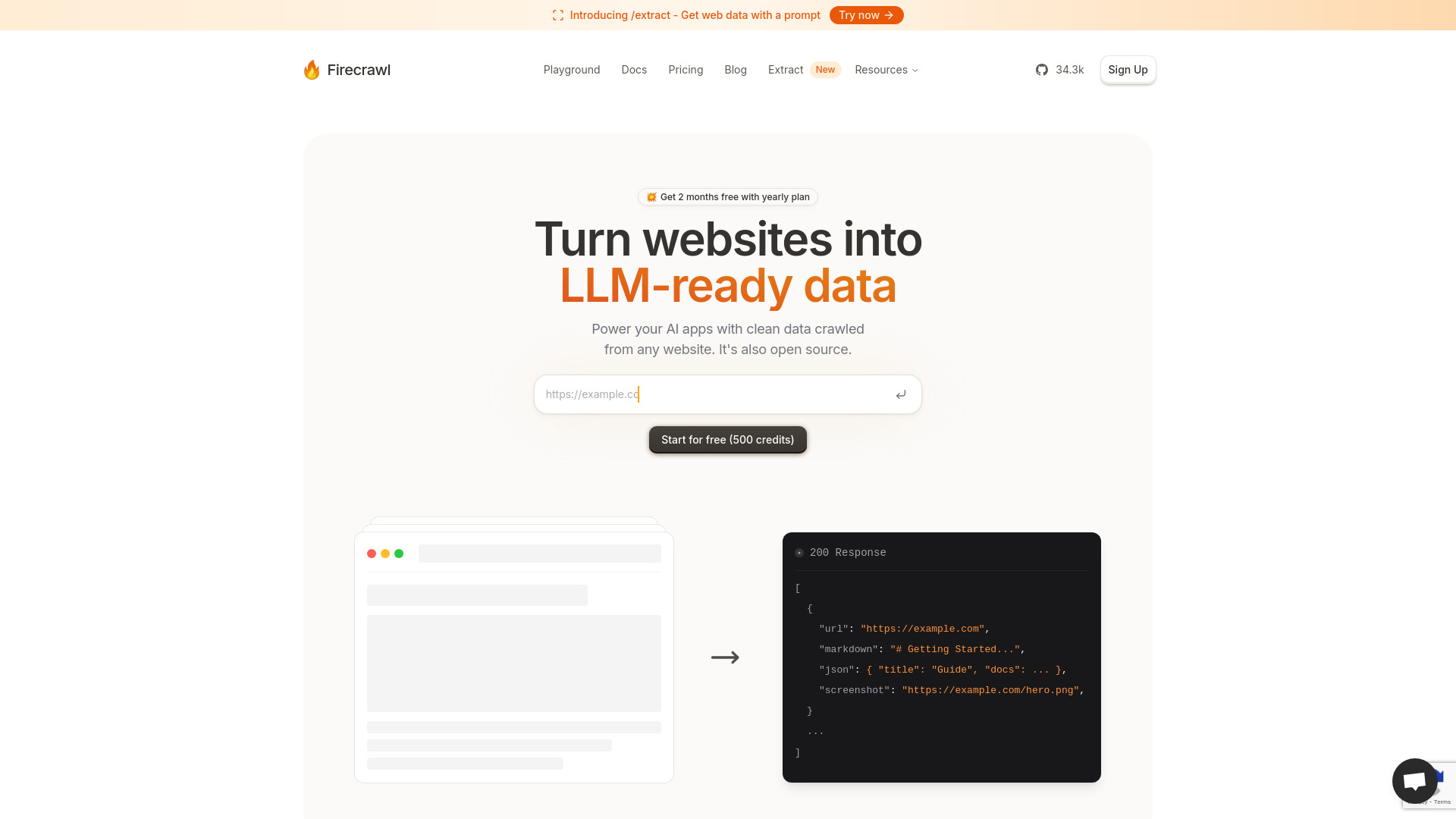
Firecrawl:高效网站数据转换与爬取工具
Firecrawl是一款专业的网站数据转换与爬取工具,能够将网站内容转换为适合大型语言模型(LLM)处理的数据格式。它集成了强大的抓取和爬取功能,为用户提供高效、准确的网站数据采集和处理解决方案。无论是内容分析、数据挖掘还是AI训练,Firecrawl都能满足用户多样化的需求。
功能特性
Firecrawl具备以下核心功能特性:
| 功能特性 | 描述 |
|---|---|
| 网站数据抓取 | 支持单页面和多页面数据抓取,可提取文本、图片、链接等多种内容 |
| 智能内容转换 | 将抓取的网站数据自动转换为适合LLM处理的格式,如JSON、Markdown等 |
| 深度爬取功能 | 支持设置爬取深度,可按照用户需求进行多层级网站内容爬取 |
| 数据清洗与处理 | 内置数据清洗功能,可去除噪音内容,提取有价值信息 |
| API接口支持 | 提供完善的API接口,便于与其他系统集成和自动化处理 |
使用方法
Firecrawl的使用方法简单直观,主要步骤如下:
| 步骤 | 操作说明 |
|---|---|
| 1. 安装配置 | 下载并安装Firecrawl工具,根据需求进行基本配置 |
| 2. 设置参数 | 指定目标网站URL、爬取深度、输出格式等参数 |
| 3. 启动任务 | 执行抓取或爬取命令,工具开始自动处理网站数据 |
| 4. 监控进度 | 实时查看任务执行状态,了解数据采集进度 |
| 5. 获取结果 | 任务完成后,获取转换后的数据,可直接用于LLM处理 |
应用场景
Firecrawl可广泛应用于多种场景:
| 应用场景 | 具体应用 |
|---|---|
| 内容分析与挖掘 | 用于网站内容分析、关键词提取、主题建模等 |
| AI训练数据准备 | 为大语言模型训练准备高质量、结构化的文本数据 |
| 竞争情报收集 | 自动收集竞争对手网站信息,进行市场分析 |
| 知识库构建 | 从专业网站抓取内容,构建行业知识库 |
| 网站数据迁移 | 辅助网站改版或数据迁移,保留有价值内容 |
技术特点
Firecrawl的技术优势体现在以下方面:
| 技术特点 | 优势说明 |
|---|---|
| 高效爬取引擎 | 采用异步处理技术,大幅提升数据采集效率 |
| 智能内容识别 | 利用AI技术识别网页主体内容,过滤广告和无关信息 |
| 灵活的数据转换 | 支持多种输出格式,满足不同LLM的输入要求 |
| 强大的反爬虫应对 | 内置多种反爬虫策略,确保数据采集稳定性 |
| 可扩展架构 | 模块化设计,支持自定义插件和功能扩展 |
相关问题与解答
问题1:Firecrawl与其他网站爬取工具有何区别? 解答:Firecrawl的独特之处在于其专为LLM优化的数据转换功能。传统爬虫工具主要关注数据采集,而Firecrawl不仅具备强大的爬取能力,还能将采集的数据智能转换为适合大型语言模型处理的格式。这意味着用户可以直接使用Firecrawl输出的数据进行AI训练或推理,无需额外的数据预处理步骤,大大提高了工作效率。 问题2:使用Firecrawl处理大型网站时有哪些性能优化建议? 解答:处理大型网站时,可采取以下优化措施:首先,合理设置爬取深度和并发请求数,避免对目标服务器造成过大压力;其次,利用Firecrawl的增量爬取功能,仅抓取更新内容;第三,使用分布式部署模式,将任务分配到多个节点并行处理;最后,根据实际需求过滤不必要的内容类型和页面,减少数据处理量。这些措施能显著提升大型网站的处理效率。